Narzędzia programisty: git (część 2)
Ostatnio spróbowaliśmy utworzyć pierwsze repozytorium, dodaliśmy coś do niego i połączyliśmy zmiany wprowadzone do pliku równolegle. Dzisiaj pokażemy sobie jak usunąć plik z listy plików do zacommitowania, rozwiązać konflikty, stworzyć listę plików ignorowanych oraz jak wrzucić efekty swojej pracy na serwer np. GitHuba.
Nie chciałem tego dodawać…
Na początek prosty przykład. W naszym testowym repozytorium dodaliśmy nowy plik test2.txt:
line a
line b
line c
Jednocześnie postanowiliśmy wyedytować stary, dobry test.txt:
line master
line 2
line 2.5
line 3
line a
line new
Teraz jeśli spróbowalibyśmy dodać test2.txt odruchowo (albo za sprawą podpowiadania w terminalu, jakie leniwi ludzie, tacy jak ja, sobie instalują) dodać zamiast tego test.txt:
# chciałem test2.txt a wyszło jak zawsze
$ git add test.txt
Co prawda, mogę jeszcze dodać właściwy plik:
$ git add test2.txt
ale nie zmieni to faktu, że ten drugi plik też tam jest.
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
modified: test.txt
new file: test2.txt
Gdyby to był np. plik konfiguracyjny, który napsuliśmy, bardzo nie chcielibyśmy go commitować do repozytorium. Na szczęście możemy to łatwo odwrócić:
$ git reset -- test.txt
Unstaged changes after reset:
M test.txt
Po sprawdzeniu okazuje się, że plik nie jest już zastageowany do commita:
$ git status
On branch master
Changes to be committed:
(use "git reset HEAD <file>..." to unstage)
new file: test2.txt
Changes not staged for commit:
(use "git add <file>..." to update what will be committed)
(use "git checkout -- <file>..." to discard changes in working directory)
modified: test.txt
Zacommitujmy zmiany zanim przejdziemy do następnego przykładu.
$ git commit -m "New file"
Istotna uwaga: istnieją polecenia takie jak git reset --hard COŚTAM. One robią coś ciutkę innego: usuwają wszystkie zmiany jakie wprowadziliśmy od czasu COŚTAM. Jest to czasami niezwykle przydatne, ale zazwyczaj nie o zniszczenie danych nam chodzi. Warto o tym wiedzieć, zanim odpalimy coś takiego u siebie, po przeczytaniu losowej porady ze StackOverflow.
Kiedy branche się kłócą w zeznaniach
Jeśli będziemy dostatecznie długo bawić się gitem, szczególnie, jeśli nie będziemy pracowali w jednoosobowych projektach, wówczas nie unikniemy sytuacji, kiedy jakieś 2 zmiany wprowadzone niezależnie do siebie w tym samym miejscu będą ze sobą konfliktować. Spróbujmy stworzyć taką sytuację, żeby zobaczyć jak zachowa się git.
Po poprzednim ćwiczeniu powinien nam zostać zmodyfikowany plik test.txt. Skorzystamy z niego, ale najpierw przejdźmy na nowego brancha:
$ git checkout -B conflict
Podrasujmy dodatkowo nasz plik:
line master
line 2
line conflict 1
line 3
line a
line new
Oprócz dodania nowej linii, zmieniliśmy również 3 linijkę w pliku. Zapiszmy zmiany, a następnie wróćmy na mastera:
$ git add test.txt
$ git commit -m "Changed line to conflict 1"
[conflict-1 376c721] Change line to conflict 1
1 file changed, 2 insertions(+), 2 deletions(-)
$ git checkout master
Switched to branch 'master'
Wprowadzone 2 zmiany zniknęły. To spróbujmy wprowadzić inne!
line master
line 2
line conflict 2
line 3
line a
line new
Tutaj również zacommittujmy zmiany
$ git add test.txt
$ git commit -m "Change line to conflict 2"
[master 42b59de] Change line to conflict 2
1 file changed, 2 insertions(+), 2 deletions(-)
Teraz czas na chwilę prawdy. Co stanie się jeśli spróbujemy zmergować zmiany z brancha conflict na mastera? Sprawdźmy:
git merge conflict
Auto-merging test.txt
CONFLICT (content): Merge conflict in test.txt
Automatic merge failed; fix conflicts and then commit the result.
Wydaje się, że coś się nie udało. Zobaczmy sam plik:
line master
line 2
<<<<<<< HEAD
line conflict 2
=======
line conflict 1
>>>>>>> conflict
line 3
line a
line new
Okazało się, że git nie był w stanie automatycznie połączyć obu zmian w pliku. Nieco lepiej jest w przypadku ostaniej linijki: obie zmiany były identyczne, więc git nie miał problemów z ich połączeniem. Ale w kwestii trzeciej? Którą z wersji trzeciej miał wybrać? Pierwszą? Drugą? A może wziąć je obie? Tylko jak? Obok siebie? Pierwsza nad drugą? Druga nad pierwszą? Git nie wie, co chcielibyśmy zrobić.
I w zasadzie to dobrze, że nie próbuje! Gdybyście dodali ściąganie kasy z konta klienta w procedurze, a kolega, nie wiedząc o tym, dodał ja w tym samym miejscu, tylko inaczej, lepiej żeby automat nie zgadywał za nas co powinno się tam znajdywać. Zamiast tego oznaczył konfliktujące ze sobą zmiany i poprosił nas o rozwiązanie problemu. Wszystko między<<<<<<< HEAD a ======= to zmiany z wersji na masterze. Z kolei od ======= do >>>>>>> conflict mamy zmiany z brancha conflict. Mając podgląd na obie zmiany możemy wybrać dowolny sposób rozwiązania problemu jaki nam pasuje, np.:
line master
line 2
line no conflict
line 3
line a
line new
Wypada pamiętać o skasowaniu tych znaczków, którymi git oznacza konflikty. Są one tym tylko po to abyśmy zwrócili na nie uwagę (oraz, aby programy z nimi nie mogły się skompilować, przez co nie możemy ich tak łatwo przegapić).
Po rozwiązaniu konfliktów w pliku zastagujmy go:
$ git add test.txt
gdy oznaczymy wszystkie konflikty jako rozwiązane, będziemy mogli powiedzieć gitowy, aby dokończył merga:
git commit
[master af70c61] Merge branch 'conflict'
Pliki na cenzurowanym
Pewnych plików nigdy nie chcieliby wrzucać do repozytorium. Przykłady: logi, skompilowane wersje programów oraz wszelkie inne śmieci powstałe podczas budowania, pliki konfiguracyjne zawierające hasła.
Byłoby ciutkę upierdliwe, gdybyśmy musieli zapisywać gdzieś taką listę i każdorazowo sprawdzać, czy przypadkiem coś z niej nie znalazło się w commicie. Dlatego git posiada taką funkcjonalność już wbudowaną: są nią pliki .gitignore. (Tak, jest tam kropka na początku. Nie, nie ma żadnego dodatkowego rozszerzenia za e. Tak, tworzenie plików o takiej nazwie pod Windowsem bywa czasem uciążliwe).
Spróbujmy utworzyć taki plik i zapisać go w naszym katalogu:
*.log
*.exe
Jeśli teraz wrzucimy do katalogu jakieś pliki exe albo logi, git status zignoruje je.
On branch master
Untracked files:
(use "git add <file>..." to include in what will be committed)
.gitignore
nothing added to commit but untracked files present (use "git add" to track)
(Czego git nie zignoruje to samego pliku .gitignore - jest to plik jak każdy inny i wypadałoby go zacommitować, żeby git zawsze konsekwentnie ignorował te same pliki).
git add z kolei powiadomi, że prawdopodobnie nie chcemy ich dodawać.
The following paths are ignored by one of your .gitignore files:
log.log
Use -f if you really want to add them.
Zacommitujmy plik .gitignore do repozytorium dla potomności:
$ git add .gitignore
$ git commit -m "Ignore .log and .exe"
[master 92a4a76] Ignore .log and .exe
1 file changed, 3 insertions(+)
create mode 100644 .gitignore
Sharing is caring
Git replamuje się jako rozproszony system wersji. To oznacza, że każdy kontrybutor w projekcie ma na swoim komputerze swoją kopię całej historii i w zasadzie w wszystkiego (dla odmiany systemy takie jak SVN trzymały wszystko na serwerze, a użytkownik musiał być połączony, żeby obejrzeć logi, zrobić commita albo zmienić brancha). Tylko, że trzeba byłoby się nią jakoś wymieniach i synchronizować ją ze sobą.
Jest to osiągane poprzez zdalne repozytoria, na które użytkownicy pchają swoje zmiany (push), albo je ściągają (pull). Najpopularniejszą obecnie platformą do tego jest GitHub. Spróbujmy zobaczyć jak działa.
Na początek zarejestrujmy się. Do tego nie potrzeba jakiejś szczególnej instrukcji.
Nastęnie będziemy mogli utworzyć nasze pierwsze repozytorium.
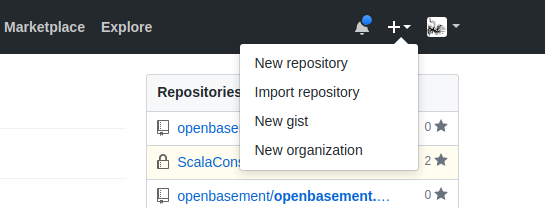
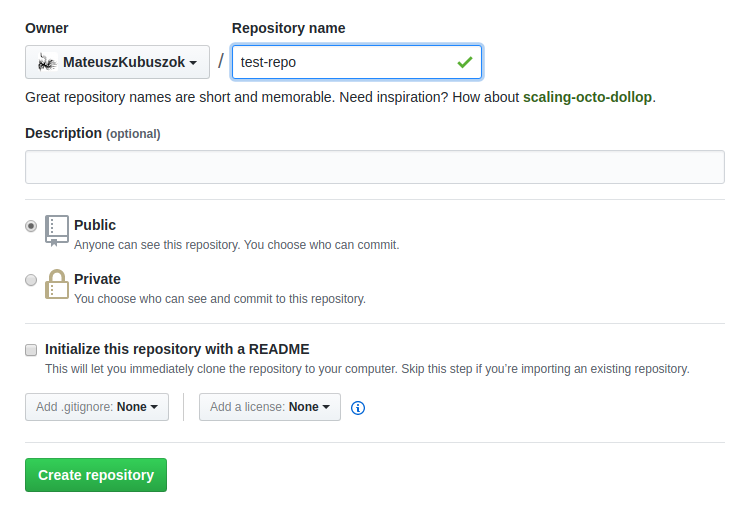
Kiedy już to zrobimy, spróbujmy wybrać ustawienie przy pomocy HTTPS.
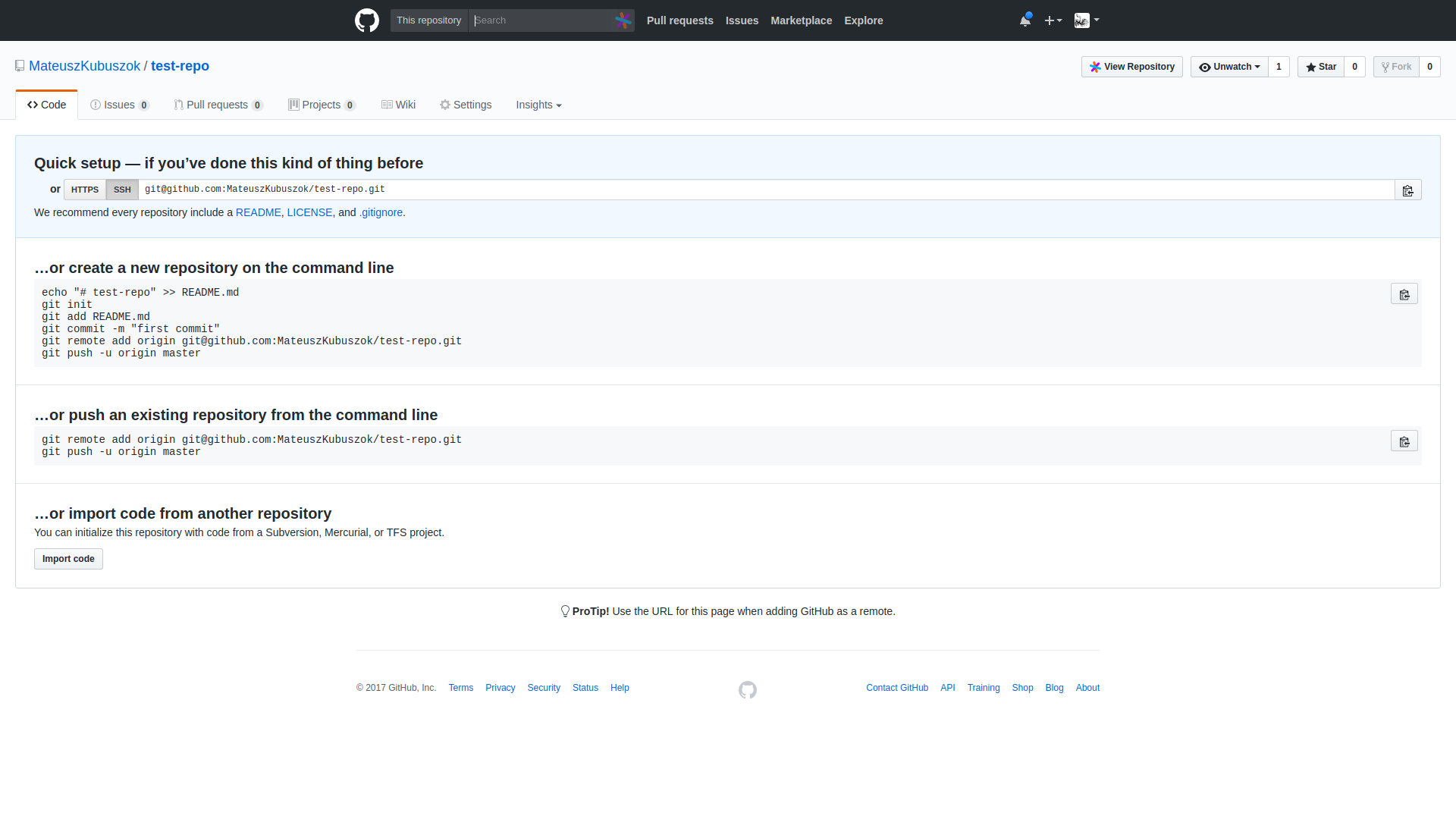
W moim przypadku oznaczało to skopiowanie linijek:
$ git remote add origin https://github.com/MateuszKubuszok/test-repo.git
$ git push -u origin master
Jeśli nie chcecie każdorazowo wpisywać nazwy użytkownika i hasła, spróbujcie dać https://nazwaużytkownika@github.com/...:
$ git remote add origin https://MateuszKubuszok@github.com/MateuszKubuszok/test-repo.git
## lub jeśli już dodaliśmy URL i chcemy go zmienić
$ git remote set-url origin https://MateuszKubuszok@github.com/MateuszKubuszok/test-repo.git
Po zakończeniu komendy git push origin master branch master na GitHubie wyświetli nam wszystko, co dodaliśmy do repozytorium.
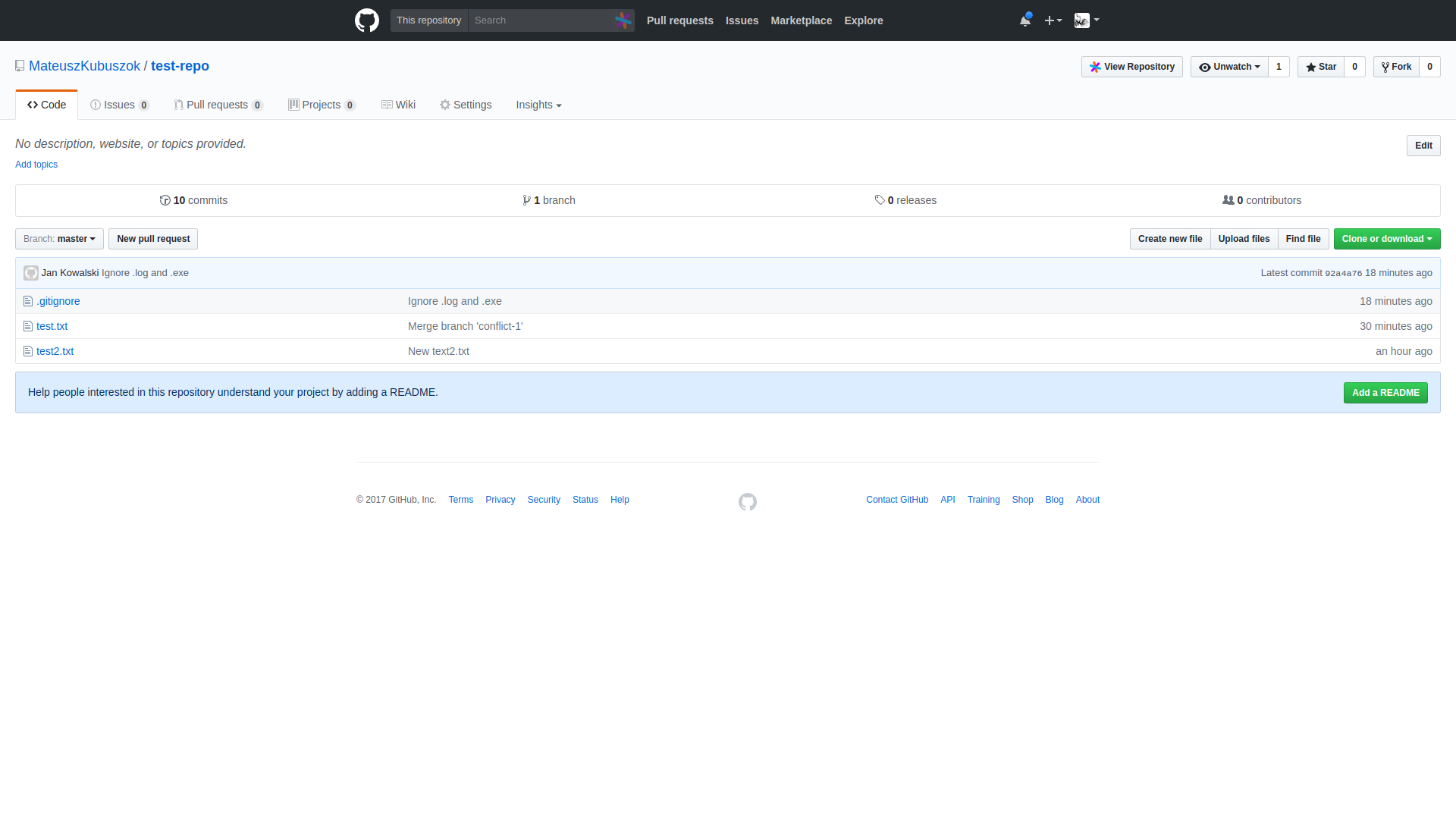
Gdybyśmy chcieli z kolei pobrać zmiany, do tego jest polecenie git pull origin master.
Ponownie uwaga: origin jest tutaj nadaną przez nas nazwą na zdalne repozytorium do którego wrzucamy swoje zmiany i z którego pobieramy zmiany. Tak więc git pull origin master należy tłumaczyć, jako pobierz zmiany z brancha master na repozytorium zdalnym origin i dodaj je do brancha na którym jestem w tej chwili, zaś git push origin master dodaj zmiany z obecnego brancha do brancha master na repozytorium zdalnym origin . Parametr -u sugerowany nam przez GitHuba sprawi, że od tej pory obecny branch z którego robiliśmy pusha (zakładamy, że jest to master), będzie domyślnie wrzucał zmiany na origin master. Jeśli jednak przejdziemy na innego brancha, wówczas git będzie domagał się o jawne podanie repozytorium oraz brancha.
W ten sposób możemy zacząć publikować nasze pierwsze programistyczne projekty w internecie.
Parę słów na koniec
Po dzisiejszych przykładach powinniśmy znać już pewne podstawy. Oczywiście aby były coś warte, należałoby je przećwiczyć nieco w praktyce.
Podczas użytkowania gita warto się konsultować ` git help`, aby uzyskać informacje na temat poszczególnych poleceń. W przypadku problemów warto googlować odpowiedzi - większość będzie już dostępna na StackOverflow.
Po opanowaniu podstaw warto doczytać o takich tematach jak git rebase, git blame, git bisect czy gitflow. Ciekawym wstępem jest interaktywny tutorial zrobiony przez jednego z użytkowników GitHuba. Co prawda wymaga Rubyego, ale był całkiem spoko.
Warto być również świadomym istnienia alternatyw do GitHuba. Do open sourcowych projektów ciekawą alternatywą jest GitLab (zwłaszcza, jeśli chciałbyś hostować go u siebie), zaś do małych prywatnych projektów, których kodu nie chcielibyście udostępniać sprawdźcie BitBucketa. Do 5 osób w projekcie jest za darmo.
To tyle na dziś. Powodzenia!